【MySQL】 单表访问方法
【MySQL】 单表访问方法
Metadata
title: 【MySQL】 单表访问方法
date: 2023-06-22 23:07
tags:
- 行动阶段/完成
- 主题场景/数据存储
- 笔记空间/KnowladgeSpace/ProgramSpace/BasicsSpace
- 细化主题/数据存储
categories:
- 数据存储
keywords:
- 数据存储
description: 【MySQL】 单表访问方法
概述
- MySQL Server使用查询优化器对查询语句进行优化,生成执行计划。
- 单表查询的访问方法主要有两种:全表扫描和使用索引。
- 全表扫描通过逐行扫描表中的记录来找到符合搜索条件的记录。
- 使用索引可以细分为多种类型,如针对主键或唯一二级索引的等值查询、普通二级索引的等值查询、索引列的范围查询和直接扫描整个索引等。
- const访问方法是通过主键或唯一二级索引来定位一条记录,具有常数级别的访问代价。
- ref访问方法适用于普通二级索引,其访问代价取决于等值匹配到的二级索引记录条数。
- ref_or_null访问方法是针对二级索引列值为NULL的情况。
- range访问方法用于处理使用IN操作符或范围查询的情况。
- index访问方法是直接通过遍历索引的叶子节点来执行查询,适用于查询列表只涉及索引列且搜索条件只包含索引中的列的情况。
- all访问方法是全表扫描的方式执行查询。
- 在使用二级索引进行查询时,需要注意二级索引+回表的操作,回表操作是在找到索引记录后再根据主键获取完整的用户记录进行进一步过滤。
- 对于range访问方法,需要明确定义范围区间,利用索引列和常数的比较操作符来构建区间。
- 索引合并有Intersection合并和Union合并两种方式,Intersection合并适用于多个二级索引的等值匹配,Union合并适用于多个二级索引的并集操作,Sort-Union合并用于多个二级索引查询结果的排序和合并。
- 联合索引可以替代Intersection索引合并的方式。
【MySQL】 单表访问方法
MySQL Server 有一个称为查询优化器的模块,一条查询语句进行语法解析之后就会被交给查询优化器来进行优化,优化的结果就是生成一个所谓的执行计划
访问方法(access method)的概念
对于单个表的查询来说,设计MySQL的大叔把查询的执行方式大致分为下边两种:
使用全表扫描进行查询
把表的每一行记录都扫一遍嘛,把符合搜索条件的记录加入到结果集就完了。
使用索引进行查询
使用索引来执行查询的方式五花八门,又可以细分为许多种类:
- 针对主键或唯一二级索引的等值查询
- 针对普通二级索引的等值查询
- 针对索引列的范围查询
- 直接扫描整个索引
MySQL 执行查询语句的方式称之为访问方法或者访问类型
const
SELECT * FROM single_table WHERE id = 1438;
SELECT * FROM single_table WHERE key2 = 3841;
SELECT * FROM single_table WHERE key2 IS NULL;
- 聚簇索引
- 唯一二级索引
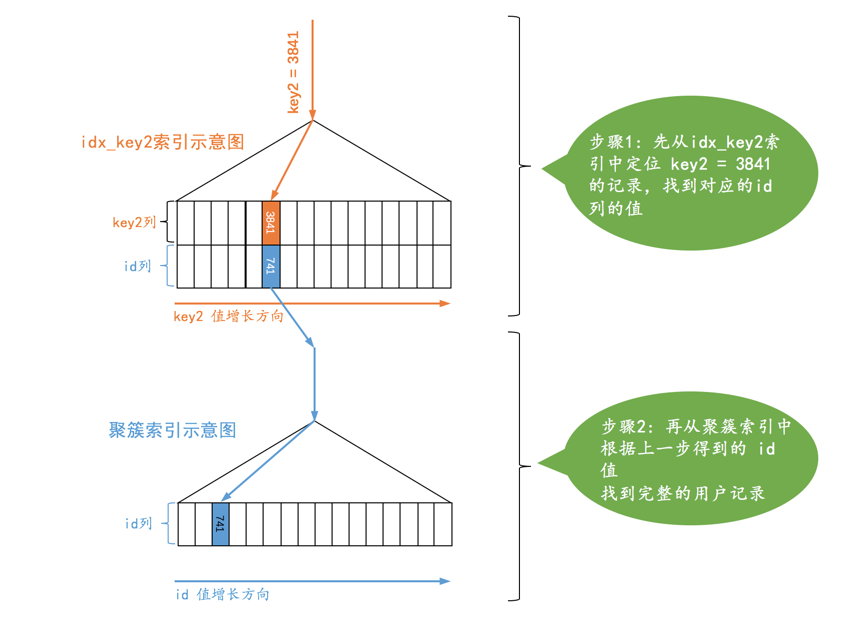
B+ 树叶子节点中的记录是按照索引列排序的,对于的聚簇索引来说,它对应的B+ 树叶子节点中的记录就是按照id 列排序的。
把这种通过主键或者唯一二级索引列来定位一条记录的访问方法定义为: const ,意思是常数级别的,代价是可以忽略不计的
ref
SELECT * FROM single_table WHERE key1 = 'abc';
普通的二级索引
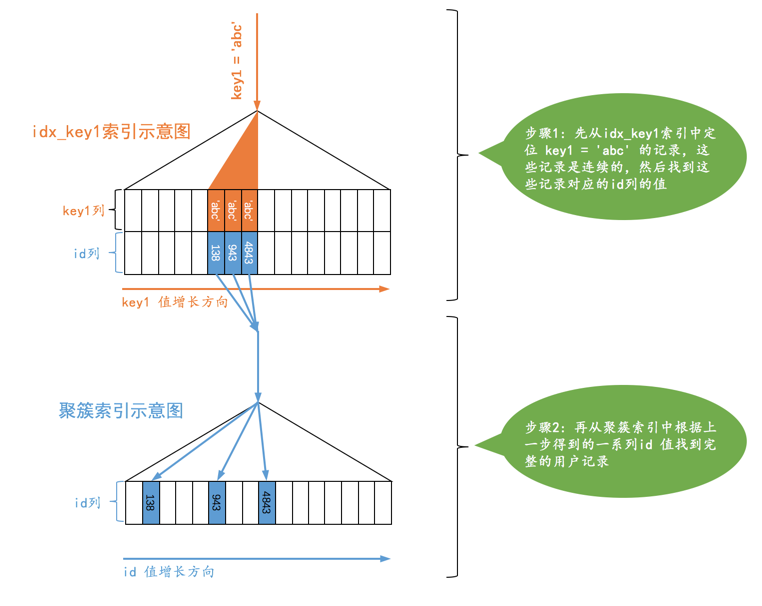
使用二级索引来执行查询的代价取决于等值匹配到的二级索引记录条数
- 二级索引列值为NULL 的情况
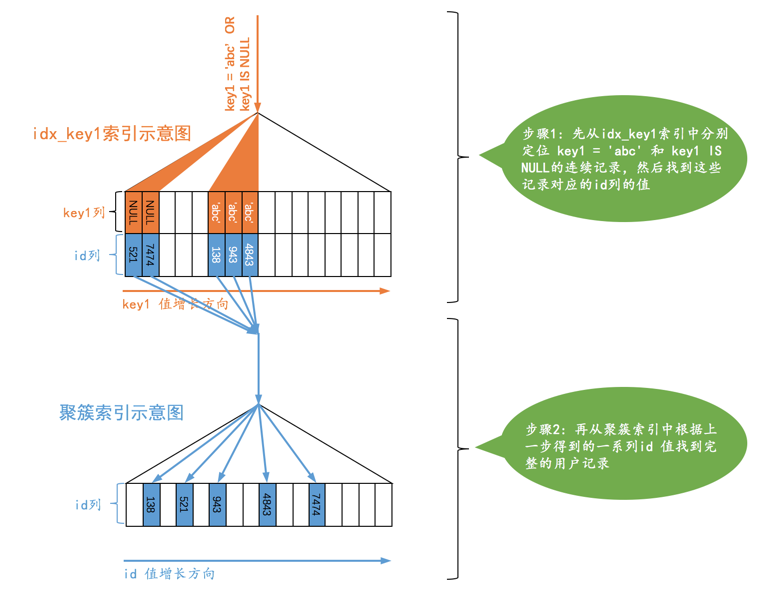
采用key IS NULL 这种形式的搜索条件最多只能使用ref 的访问方法,而不是const 的访问方法。
对于某个包含多个索引列的二级索引来说,只要是最左边的连续索引列是与常数的等值比较就可能采用ref的访问方法
ref_or_null
SELECT * FROM single_demo WHERE key1 = 'abc' OR key1 IS NULL;
range
SELECT * FROM single_table WHERE key2 IN (1438, 6328) OR (key2 >= 38 AND key2 <= 79);
index
SELECT key_part1, key_part2, key_part3 FROM single_table WHERE key_part2 = 'abc';
这个查询符合下边这两个条件:
- 它的查询列表只有3个列: key_part1 , key_part2 , key_part3 ,而索引idx_key_part 又包含这三个列。
- 搜索条件中只有key_part2 列。这个列也包含在索引idx_key_part 中。
可以直接通过遍历idx_key_part 索引的叶子节点的记录来比较key_part2 = ‘abc’ 这个条件是否成立
把匹配成功的二级索引记录的key_part1 , key_part2 , key_part3 列的值直接加到结果集中就行了。
all
全表扫描执行查询的方式称之为: all 。
注意事项
重温 二级索引 + 回表
因为二级索引的节点中的记录只包含索引列和主键,所以在步骤1中使用idx_key1 索引进行查询时只会用到与key1 列有关的搜索条件,其余条件,比如key2 > 1000 这个条件在步骤1中是用不到的,只有在步骤2完成回表操作后才能继续针对完整的用户记录中继续过滤。
明确range访问方法使用的范围区间
其实对于B+ 树索引来说,只要索引列和常数使用= 、<=> 、IN 、NOT IN 、IS NULL 、IS NOT NULL 、> 、< 、>= 、<= 、BETWEEN 、!= (不等于也可以写成<> )或者LIKE 操作符连接起来,就可以产生一个所谓的区间。
索引合并
Intersection合并
在二级索引列都是等值匹配的情况下才可能使用Intersection 索引合并,是因为只有在这种情况下根据二级索引查询出的结果集是按照主键值排序的。
读取多个二级索引后取交集
Union合并
读取多个二级索引后取集
采用Union 索引合并的方式把 Or 连接的两个主键集合取并集,然后进行回表操作,将结果返回给用户。
SELECT * FROM single_table WHERE key_part1 = 'a' AND key_part2 = 'b' AND key_part3 = 'c' OR (key1 = 'a' AND key3 = 'b');
- 先按照搜索条件key1 = ‘a’ AND key3 = ‘b’ 从索引idx_key1 和idx_key3 中使用Intersection 索引合并的方式得到一个主键集合。
- 再按照搜索条件key_part1 = ‘a’ AND key_part2 = ‘b’ AND key_part3 = ‘c’ 从联合索引idx_key_part 中得到另一个主键集合。
- 采用Union 索引合并的方式把上述两个主键集合取并集,然后进行回表操作,将结果返回给用户。
Sort-Union合并
读取多个二级索引后对结果按主键排序并返回合并
SELECT * FROM single_table WHERE key1 < 'a' OR key3 > 'z'
- 先根据key1 < ‘a’ 条件从idx_key1 二级索引总获取记录,并按照记录的主键值进行排序
- 再根据key3 > ‘z’ 条件从idx_key3 二级索引总获取记录,并按照记录的主键值进行排序
- 因为上述的两个二级索引主键值都是排好序的,剩下的操作和Union 索引合并方式就一样了。
联合索引替代Intersection索引合并
 wechat
wechat alipay
alipay