【MySQL】 连接的原理
【MySQL】 连接的原理
Metadata
title: 【MySQL】 连接的原理
date: 2023-06-23 13:26
tags:
- 行动阶段/完成
- 主题场景/数据存储
- 笔记空间/KnowladgeSpace/ProgramSpace/BasicsSpace
- 细化主题/数据存储
categories:
- 数据存储
keywords:
- 数据存储
description: 【MySQL】 连接的原理
概述
连接简介:
- 连接的本质是通过笛卡尔积将两个表中的记录相互匹配组合。
- 连接过程涉及单表条件和涉及两表条件。
- 连接查询的执行过程包括确定驱动表和在驱动表和被驱动表之间查找匹配记录。
- 连接分为内连接和外连接,内连接只返回匹配的记录,而外连接会包括未匹配的记录。
- 外连接可以进一步细分为左外连接和右外连接。
连接的原理总结:
- 嵌套循环连接是一种连接算法,驱动表只访问一次,而被驱动表可能被多次访问。
- 使用索引可以加快连接速度。
- 基于块的嵌套循环连接是优化的方法,通过减少被驱动表的访问次数来提高性能。
- 基于块的嵌套循环连接使用join buffer来加载驱动表的记录,然后一次性和被驱动表的多条记录进行匹配,减少了磁盘访问的开销。
- 执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer 中
- 然后开始扫描被驱动表
- 每一条被驱动表的记录一次性和join buffer 中的多条驱动表记录做匹配
- 因为匹配的过程都是在内存中完成的
- 基于块的嵌套循环连接也被称为Block Nested-Loop Join算法。
连接简介
连接的本质
笛卡尔积
连接查询的结果集中包含一个表中的每一条记录与另一个表中的每一条记录相互匹配的组合
连接过程简介
- 涉及单表的条件
- 涉及两表的条件
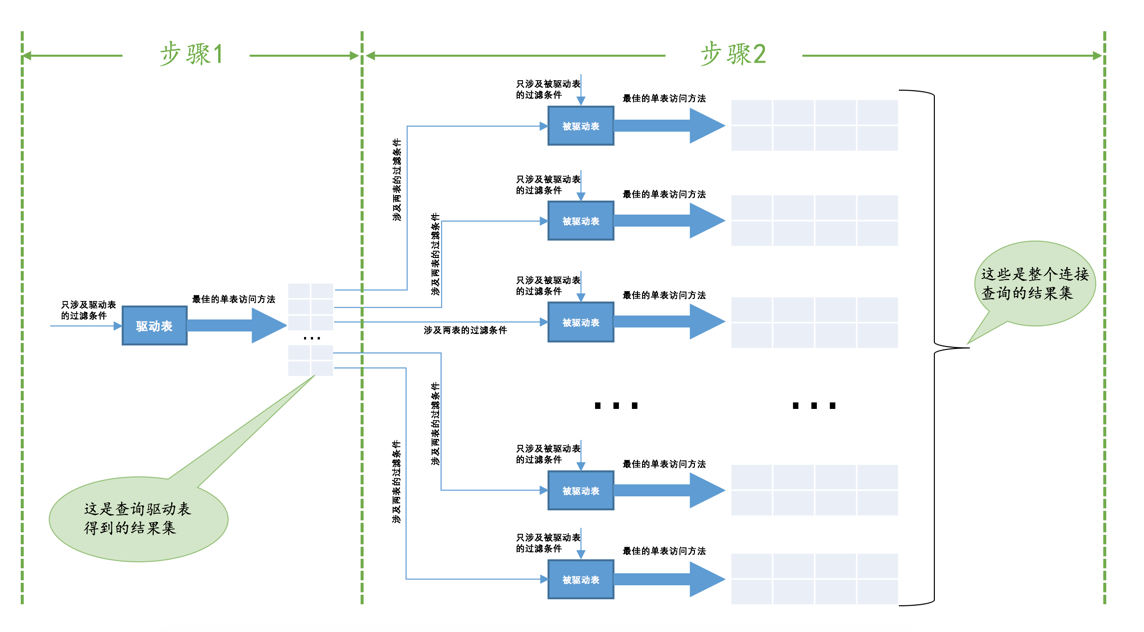
这个连接查询的大致执行过程
- 首先确定第一个需要查询的表,这个表称之为驱动表
- 针对上一步骤中从驱动表产生的结果集中的每一条记录,分别需要到t2 表中查找匹配的记录,所谓匹配的记录,指的是符合过滤条件的记录。
内连接和外连接
- 对于内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加入到最后的结果集,我们上边提到的连接都是所谓的内连接。
- 对于外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集。
在MySQL 中,根据选取驱动表的不同,外连接仍然可以细分为2种: - 左外连接
- 选取左侧的表为驱动表。
- 右外连接
- 选取右侧的表为驱动表。
外连接的语法
对于左(外)连接和右(外)连接来说,必须使用ON 子句来指出连接条件。
内连接的语法
内连接和外连接的根本区别
内连接和外连接的根本区别就是在驱动表中的记录不符合ON 子句中的连接条件时不会把该记录加入到最后的结果集
由于在内连接中ON子句和WHERE子句是等价的,所以内连接中不要求强制写明ON子句
对于内连接来说,驱动表和被驱动表是可以互换的,并不会影响最后的查询结果。
左外连接和右外连接的驱动表和被驱动表不能轻易互换
连接的原理
嵌套循环连接(Nested-Loop Join)
驱动表只访问一次,但被驱动表却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录条数
使用索引加快连接速度
基于块的嵌套循环连接(Block Nested-Loop Join)
采用嵌套循环连接算法的两表连接过程中,被驱动表可是要被访问好多次的,如果这个被驱动表中的数据特别多而且不能使用索引进行访
尽量减少访问被驱动表的次数
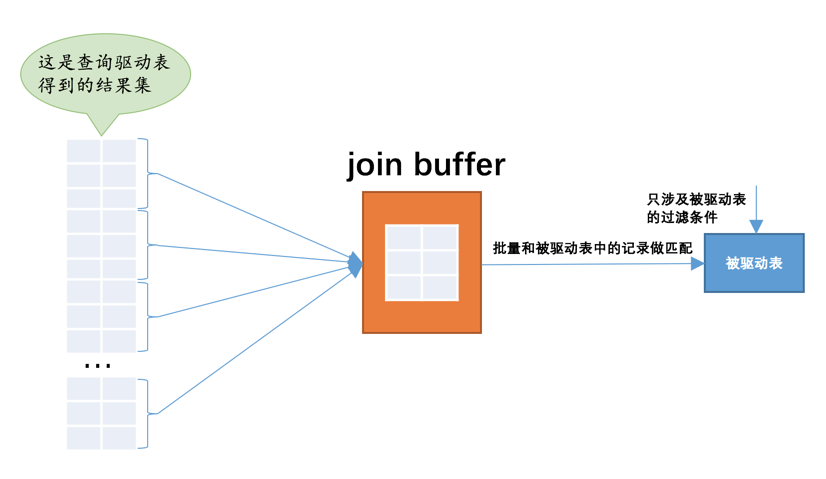
在把被驱动表的记录加载到内存的时候,一次性和多条驱动表中的记录做匹配,这样就可以大大减少重复从磁盘上加载被驱动表的代价了
join buffer 的概念
- 执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer 中
- 然后开始扫描被驱动表
- 每一条被驱动表的记录一次性和join buffer 中的多条驱动表记录做匹配
- 因为匹配的过程都是在内存中完成的
这种加入了join buffer 的嵌套循环连接算法称之为基于块的嵌套连接(Block Nested-Loop Join)算法。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 蝶梦庄生!
 wechat
wechat alipay
alipay
相关推荐
评论