【Java 多线程并发】 CAS(Compare And Swap)
【Java 多线程并发】 CAS(Compare And Swap)
Metadata
title: 【Java 多线程并发】 CAS(Compare And Swap)
date: 2023-07-03 23:52
tags:
- 行动阶段/完成
- 主题场景/程序
- 笔记空间/KnowladgeSpace/ProgramSpace/BasicsSpace
- 细化主题/Java/多线程并发
categories:
- Java
keywords:
- Java/多线程并发
description: 【Java 多线程并发】 CAS(Compare And Swap)
概述
CAS 的全称为 Compare And Swap,直译就是比较交换。
是一条 CPU 的原子指令
其作用是让 CPU 先进行比较两个值是否相等,然后原子地更新某个位置的值
其实现方式是基于硬件平台的汇编指令
它就是 CPU 的一条原子指令。过程是这样:它包含 3 个参数
- 内存位置(V)、
- 预期原值(E)
- 新值 (N)。
V 表示要更新变量的值,E 表示预期值,N 表示新值。仅当 V 值等于 E 值时,才会将 V 的值设为 N,如果 V 值和 E 值不同,则说明已经有其他线程做两个更新,则当前线程则什么都不做。
CAS的应用
- 非阻塞算法 (nonblocking algorithms)
CAS 底层原理
锁总线是通过 LOCK#信号实现的,锁缓存是通过缓存一致性协议实现的。
CAS 存在的问题
- 循环时间太长
- 只能保证一个共享变量原子操作
- ABA 问题
- CAS 造成 Cache 一致性流量过大
锁机制存在的问题
在 JDK 5 之前 Java 语言是靠 synchronized 关键字保证同步的,这会导致有锁
锁机制存在以下问题:
(1)在多线程竞争下,加锁、释放锁会导致比较多的上下文切换和调度延时,引起性能问题。
(2)一个线程持有锁会导致其它所有需要此锁的线程挂起。
(3)如果一个优先级高的线程等待一个优先级低的线程释放锁会导致优先级倒置,引起性能风险。
volatile 是不错的机制,它是通过汇编语言中的 LOCK 指令实现的,但是 volatile 不能保证原子性。因此对于同步最终还是要回到锁机制上来。
独占锁是一种悲观锁,synchronized 就是一种独占锁,会导致其它所有需要锁的线程挂起,等待持有锁的线程释放锁。
而另一个更加有效的锁就是乐观锁。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。乐观锁的缺点是不能解决脏读的问题。乐观锁用到的机制就是 CAS,(Compare and Swap)。
什么是CAS
CAS 的全称为 Compare And Swap,直译就是比较交换。是一条 CPU 的原子指令,其作用是让 CPU 先进行比较两个值是否相等,然后原子地更新某个位置的值,其实现方式是基于硬件平台的汇编指令,在 intel 的 CPU 中,使用的是 cmpxchg 指令,就是说 CAS 是靠硬件实现的,从而在硬件层面提升效率。
它是一个无锁的原子算法。所以它就是一个乐观锁,也就是不加锁。无锁也就没有加锁和解锁的过程,不存在阻塞,也就提高了效率,提高了 CPU 的吞吐量(单位时间内执行完成的操作条数就多了)
它就是 CPU 的一条原子指令。过程是这样:它包含 3 个参数
- 内存位置(V)、
- 预期原值(E)
- 新值 (N)。
V 表示要更新变量的值,E 表示预期值,N 表示新值。仅当 V 值等于 E 值时,才会将 V 的值设为 N,如果 V 值和 E 值不同,则说明已经有其他线程做两个更新,则当前线程则什么都不做。最后,CAS 返回当前 V 的真实值(在 CAS 的一些特殊情况下将仅返回 CAS 是否成功,而不提取当前 值)。CAS 操作时抱着乐观的态度进行的,它总是认为自己可以成功完成操作。
当多个线程同时使用 CAS 操作一个变量时,只有一个会胜出,并成功更新,其余均会失败。失败的线程不会挂起,仅是被告知失败,并且允许再次尝试,当然也允许实现的线程放弃操作。基于这样的原理,CAS 操作即使没有锁,也可以发现其他线程对当前线程的干扰。
与锁相比,使用 CAS 会使程序看起来更加复杂一些,但由于其非阻塞的,它对死锁问题天生免疫,并且,线程间的相互影响也非常小。更为重要的是,使用无锁的方式完全没有锁竞争带来的系统开销,也没有线程间频繁调度带来的开销,因此,它要比基于锁的方式拥有更优越的性能。
简单的说,CAS 需要你额外给出一个期望值,也就是你认为这个变量现在应该是什么样子的。如果变量不是你想象的那样,那说明它已经被别人修改过了。你就需要重新读取,再次尝试修改就好了。
CAS的应用
利用 CPU 的 CAS 指令,同时借助 JNI 来完成 Java 的非阻塞算法。其它原子操作都是利用类似的特性完成的。而整个 J.U.C 都是建立在 CAS 之上的,因此对于 synchronized 阻塞算法,J.U.C 在性能上有了很大的提升。
非阻塞算法 (nonblocking algorithms)
非阻塞算法就是一个线程的失败或者挂起不应该影响其他线程的失败或挂起的算法。非阻塞算法就需要借助 CAS 操作来实现,这也是 CAS 的一个主要应用方向。
现代的 CPU 提供了特殊的指令,可以自动更新共享数据,而且能够检测到其他线程的干扰,而 compareAndSet() 就用这些 CPU 提供的特殊指令代替了锁定。
我们来看一下 AtomicInteger 类在没有锁的情况下是如何做到数据正确性的。
public class AtomicInteger extends Number implements java.io.Serializable {
private volatile int value;
public final int get() {
return value;
}
public final int getAndIncrement() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return current;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
}
首先毫无疑问,在没有锁的机制下可能需要借助 volatile 原语,保证线程间的数据是可见的(共享的)。
private volatile int value;
这样才获取变量的值的时候才能直接读取。
public final int get() {
return value;
}
然后来看看 ++i 是怎么做到的。
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
incrementAndGet() 采用了 CAS 操作,每次从内存中读取数据然后将此数据和 + 1 后的结果进行 CAS 操作,如果成功就返回结果,否则重试直到成功为止。
incrementAndGet() 方法中的 compareAndSet() 方法则是利用 JNI 来完成 CPU 指令的操作。通过判断当前的值 this 还是不是等于一开始的值 expect,如果还等于 expect,就说明期间没有其他线程对该数据进行了修改,不会出现并发一场,那么就将 this 改成 update 更新后的数据。
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update); // 仔细注意传进来的参数,理解该方法的作用
}
整体的过程就是这样子的,通过 JNI(Java 本地调用)来调用 C 语言代码,然后 C 语言代码来调用 CPU 的 CAS 指令来完成 Java 的非阻塞算法。其它原子操作都是利用类似的特性完成的。
其中
unsafe.compareAndSwapInt(this, valueOffset, expect, update);
类似:
if (this == expect) {
this = update
return true;
} else {
return false;
}
Unsafe 是 CAS 的核心类, Java 无法直接访问底层操作系统,而是通过本地( native )方法来访问。不过尽管如此, JVM 还是开了一个后门: Unsafe ,它提供了硬件级别的原子操作, 这里的 compareAndSwapInt () 就是 Unsafe 类提供的硬件原子操作之一 。
那么问题就来了,成功过程中需要2个步骤:比较this == expect,替换this = update,compareAndSwapInt如何这两个步骤的原子性呢? 参考CAS的原理。
CAS 底层原理
归功于硬件指令集的发展,实际上,我们可以使用同步将这两个操作变成原子的,但是这么做就没有意义了。所以我们只能靠硬件来完成,硬件保证一个从语义上看起来需要多次操作的行为只通过一条处理器指令就能完成。这类指令常用的有:
- 测试并设置(Tetst-and-Set)
- 获取并增加(Fetch-and-Increment)
- 交换(Swap)
- 比较并交换(Compare-and-Swap)
- 加载链接 / 条件存储(Load-Linked/Store-Conditional)
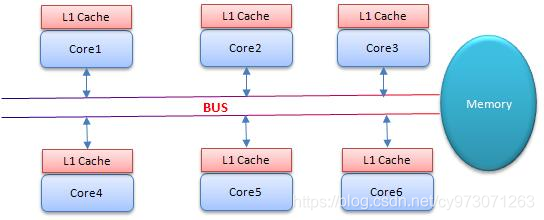
SMP(对称多处理器)架构图
- BUS:总线
- 每一个 CPU 都共用一根总线,与主内存相互交互。每一个 CPU 都有一个自己私有的 Cache
CPU 实现原子指令有 3种方式:
处理器自动保证基本内存操作的原子性
首先处理器会自动保证基本的内存操作的原子性。处理器保证从系统内存当中读取或者写入一个字节是原子的,意思是当一个处理器读取一个字节时,其他处理器不能访问这个字节的内存地址。奔腾 6 和最新的处理器能自动保证单处理器对同一个缓存行里进行 16/32/64 位的操作是原子的,但是复杂的内存操作处理器不能自动保证其原子性,比如跨总线宽度,跨多个缓存行,跨页表的访问。但是处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
通过总线锁定来保证原子性
总线锁定其实就是处理器使用了总线锁,所谓总线锁就是使用处理器提供的一个 LOCK# 信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占共享内存。但是该方法成本太大。因此有了下面的方式。
通过缓存锁定来保证原子性
在同一时刻我们只需保证对某个内存地址的操作是原子性即可,但总线锁定把 CPU 和内存之间通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,所以总线锁定的开销比较大,最近的处理器在某些场合下使用缓存锁定代替总线锁定。
所谓缓存锁定 是指内存区域如果被缓存在处理器的缓存行中,并且在 Lock 操作期间被锁定,那么当它执行操作写回到内存时,处理器不在总线上输出 LOCK# 信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改两个以上处理器缓存的内存区域数据(这里和 volatile 的可见性原理相同),当其他处理器回写已被锁定的缓存行的数据时,会使缓存行无效。
注意:有两种情况下处理器不会使用缓存锁定
- 当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行时,则处理器会调用总线锁定。
- 有些处理器不支持缓存锁定,对于 Intel 486 和 Pentium 处理器,就是锁定的内存区域在处理器的缓存行也会调用总线锁定。
总结:
锁总线是通过 LOCK#信号实现的,锁缓存是通过缓存一致性协议实现的。
CAS 存在的问题
CAS 虽然高效地解决了原子操作,但是还是存在一些缺陷的,主要表现在三个方面:循环时间太长、只能保证一个共享变量原子操作、ABA 问题。
循环时间太长
如果 CAS 一直不成功呢?这种情况绝对有可能发生,如果自旋 CAS 长时间地不成功,则会给 CPU 带来非常大的开销。在 JUC 中有些地方就限制了 CAS 自旋的次数,例如 BlockingQueue 的 SynchronousQueue。
只能保证一个共享变量原子操作
看了 CAS 的实现就知道这只能针对一个共享变量,如果是多个共享变量就只能使用锁了,当然如果你有办法把多个变量整成一个变量,利用 CAS 也不错。从 Java1.5 开始 JDK 提供了 AtomicReference 类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作。
ABA 问题
CAS 需要检查操作值有没有发生改变,如果没有发生改变则更新。但是存在这样一种情况:如果一个值原来是 A,变成了 B,然后又变成了 A,那么在 CAS 检查的时候会发现没有改变,但是实质上它已经发生了改变,这就是所谓的 ABA 问题。对于 ABA 问题其解决方案是加上版本号,即在每个变量都加上一个版本号,每次改变时加 1,即 A —> B —> A,变成 1A —> 2B —> 3A。
从 Java1.5 开始 JDK 的 atomic 包里提供了一个类 AtomicStampedReference 来解决 ABA 问题。这个类的 compareAndSet 方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。其实就类似于引入了版本概念,给每一个数据都有一个它唯一的版本号,通关检查版本号来判断数据是否被修改。
CAS 造成 Cache 一致性流量过大
现在几乎所有的锁都是可重入的,即已经获得锁的线程可以多次锁住 / 解锁监视对象,按照之前的 HotSpot 设计,每次加锁 / 解锁都会涉及到一些 CAS 操作(比如对等待队列的 CAS 操作),CAS 操作会延迟本地调用 (使本地调用不是那么及时),因此偏向锁的想法是 一旦线程第一次获得了监视对象,之后让监视对象 “偏向” 这个线程,之后的多次调用则可以避免 CAS 操作,说白了就是置个变量,如果发现为 true 则无需再走各种加锁 / 解锁流程。轻量级锁就是基于 CAS 操作的
CAS 为什么会引入本地延迟?这要从 SMP(对称多处理器)架构说起,下图大概表明了 SMP 的结构:
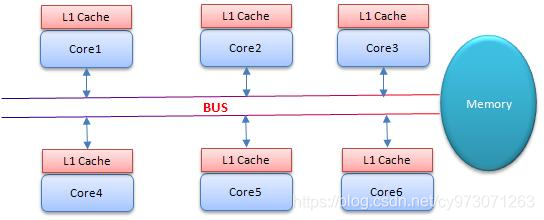
SMP(对称多处理器)架构
其意思是 所有的 CPU 会共享一条系统总线(BUS),靠此总线连接主存。每个核都有自己的一级缓存,各核相对于 BUS 对称分布,因此这种结构称为 “对称多处理器”。
而 CAS 的全称为 Compare-And-Swap,是一条 CPU 的原子指令,其作用是让 CPU 比较后原子地更新某个位置的值,其实现方式是基于硬件平台的汇编指令,就是说 CAS 是靠硬件实现的,JVM 只是封装了汇编调用,那些 AtomicInteger 类便是使用了这些封装后的接口。
例如:Core1 和 Core2 可能会同时把主存中某个位置的值 Load 到自己的 L1 Cache 中,当 Core1 在自己的 L1 Cache 中修改这个位置的值时,会通过总线,使 Core2 中 L1 Cache 对应的值 “失效”,而 Core2 一旦发现自己 L1 Cache 中的值失效(称为 Cache 命中缺失)则会通过总线从内存中加载该地址最新的值,大家通过总线的来回通信称为 “Cache 一致性流量”,因为总线被设计为固定的 “通信能力”,如果 Cache 一致性流量过大,总线将成为瓶颈。而当 Core1 和 Core2 中的值再次一致时,称为 “Cache 一致性”,从这个层面来说,锁设计的终极目标便是减少 Cache 一致性流量。
而 CAS 恰好会导致 Cache 一致性流量,如果有很多线程都共享同一个对象,当某个 Core CAS 成功时必然会引起总线风暴,这就是所谓的本地延迟,本质上偏向锁就是为了消除 CAS,降低 Cache 一致性流量。
相关参考:
Cache 一致性:
上面提到 Cache 一致性,其实是有协议支持的,现在通用的协议是 MESI(最早由 Intel 开始支持),具体参考:http://en.wikipedia.org/wiki/MESI_protocol。
Cache 一致性流量的例外情况:
其实也不是所有的 CAS 都会导致总线风暴,这跟 Cache 一致性协议有关,具体参考:http://blogs.oracle.com/dave/entry/biased_locking_in_hotspot
NUMA(Non Uniform Memory Access Achitecture)架构:
与 SMP 对应还有非对称多处理器架构,现在主要应用在一些高端处理器上,主要特点是没有总线,没有公用主存,每个 Core 有自己的内存,针对这种结构此处不做讨论。
concurrent包的实现
由于java的CAS同时具有 volatile 读和volatile写的内存语义,因此Java线程之间的通信现在有了下面四种方式:
- A线程写volatile变量,随后B线程读这个volatile变量。
- A线程写volatile变量,随后B线程用CAS更新这个volatile变量。
- A线程用CAS更新一个volatile变量,随后B线程用CAS更新这个volatile变量。
- A线程用CAS更新一个volatile变量,随后B线程读这个volatile变量。
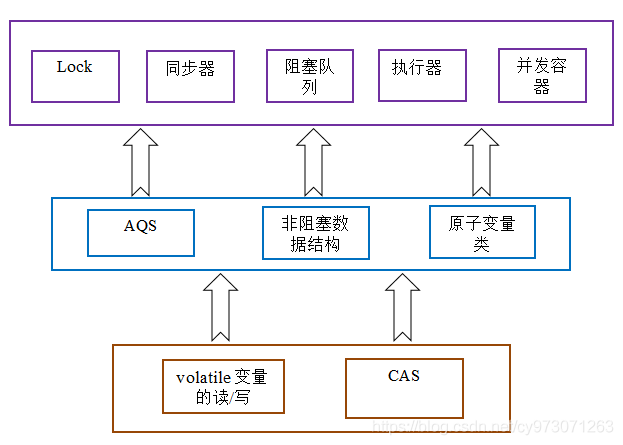
Java的CAS会使用现代处理器上提供的高效机器级别原子指令,这些原子指令以原子方式对内存执行读-改-写操作,这是在多处理器中实现同步的关键(从本质上来说,能够支持原子性读-改-写指令的计算机器,是顺序计算图灵机的异步等价机器,因此任何现代的多处理器都会去支持某种能对内存执行原子性读-改-写操作的原子指令)。同时,volatile变量的读/写和CAS可以实现线程之间的通信。把这些特性整合在一起,就形成了整个concurrent包得以实现的基石。如果我们仔细分析concurrent包的源代码实现,会发现一个通用化的实现模式:
- 首先,声明共享变量为volatile;
- 然后,使用CAS的原子条件更新来实现线程之间的同步;
- 同时,配合以volatile的读/写和CAS所具有的volatile读和写的内存语义来实现线程之间的通信。
AQS和非阻塞数据结构和原子变量类(java.util.concurrent.atomic包中的类),这些concurrent包中的基础类都是使用这种模式来实现的,而concurrent包中的高层类又是依赖于这些基础类来实现的。从整体来看,concurrent包的实现示意图如下:
 wechat
wechat alipay
alipay